Backup vs Disaster Recovery
One of the most common misconceptions in IT strategy is the belief that backup equals recovery. Backups preserve copies of data. Disaster recovery defines how quickly and completely your entire business environment can be restored after an incident.
An organisation can have reliable backups and still be unable to recover its operations within an acceptable timeframe. Recoverability requires planning, orchestration and validation, not just data protection.
Backup alone does not address the infrastructure, rebuild time, application dependencies, identity systems, network configuration or failover orchestration. For that, you need a disaster recovery strategy.
For a deeper breakdown, read our blog Why Backup and Disaster Recovery are not equal.
Why your business needs a disaster recovery plan
In recent years, the risks facing organisations have evolved significantly. What’s changed is not just the frequency of disruption, but also the speed at which it impacts the business.
The question now is not whether your business will face a disruptive event, but whether you will be able to recover from it quickly enough to protect your revenue, customers, reputation and compliance obligations.
The cost of downtime and business impact
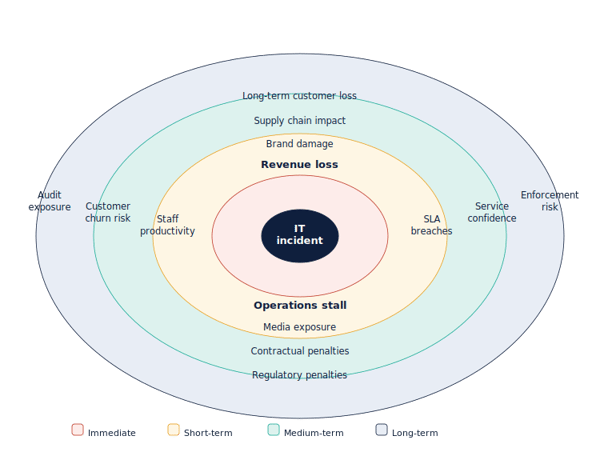
Unplanned downtime is no longer just an IT issue - it is a direct commercial risk that carries a cost that goes well beyond the IT team.
The financial exposure varies by sector and business model, but the impact builds across several areas, including:
-
Revenue lost during the period of unavailability
-
Reduced productivity across all staff who depend on IT systems
-
Customer churn risk where service availability is central to the relationship
-
Brand and reputational damage that outlasts the incident itself
-
Contractual penalties where SLAs have been breached
In many cases, the longer-term consequences - particularly reputational damage and customer loss - exceed the immediate financial impact of the outage itself.
Commercial and regulatory drivers
As a result, disaster recovery has become a board-level concern, not just a technical consideration. Businesses today face a growing set of commercial and regulatory obligations that require them to demonstrate a working disaster recovery capability.
For a more in-depth look at how disaster recovery is impacting board level conversations, read our blog Why disaster recovery testing is a board-level priority.
Areas of consideration include:
-
Revenue continuity: boards and investors increasingly want evidence of operational resilience planning.
-
Customer trust: enterprise procurement and supply chain frameworks often require DR evidence, as seen in the Cyber Security and Resilience Bill
-
Contractual SLAs: customers and partners may include uptime commitments that depend on recovery capability
-
Insurance requirements: cyber insurance underwriting increasingly asks about backup, DR testing and recovery architecture
-
Supply chain resilience: disruption to your systems may have downstream consequences for your customers and partners
-
Reputational protection: public incidents involving prolonged downtime carry lasting commercial consequences
-
Regulatory audit evidence: sectors including financial services, healthcare, and legal require demonstrable recovery capability. Regulatory frameworks such as those influenced by the Financial Conduct Authority are placing increasing emphasis on demonstrable recovery capability, not just documented plans.
For organisations operating in regulated industries, these obligations become more defined and more strictly enforced. Requirements around data protection, operational resilience and auditability place additional pressure on organisations to demonstrate not just recovery capability, but proven recovery performance.
While regulatory and commercial pressures are increasing, the need to demonstrate recovery capability against real-world threats - particularly ransomware - is actively testing whether that capability will hold under pressure.
How disaster recovery services have changed
Disaster recovery services have evolved significantly over the past decade. Where recovery was once focused on restoring data from backup over hours or days, modern organisations now require near-continuous availability, minimal data loss, and fully validated recovery capability.
The most significant change is not just in technology, but in expectation - recovery is no longer about restoration alone, but about maintaining business continuity and disaster recovery capability under real-world conditions. In modern environments, recovery is no longer measured by whether systems can be restored, but by how quickly the business can return to normal operation.
The IT environments that disaster recovery needs to protect have also changed fundamentally, and recovery strategies have had to evolve to keep pace. Legacy approaches, often built around on-premise infrastructure and tape-based backup, are no longer sufficient for the way modern businesses operate. Instead, organisations must account for more complex, distributed environments and a rapidly evolving threat landscape.
Several key trends have driven this shift, including:
Cloud-First and Hybrid Infrastructure
Most organisations now operate across a combination of private cloud, public cloud, SaaS platforms and on-premise infrastructure. According to recent reports from IBM, in 2025 30% of all data breaches involved data spread across multiple environments, including public cloud, private cloud and on-premise infrastructure. These incidents are typically more complex, take longer to contain, and carry significantly higher remediation costs.
As a result, disaster recovery services and recovery strategies must account for multiple environments - each with its own recovery mechanisms, shared responsibility models, and service boundaries.
SaaS, Disaster Recovery and the Shared Responsibility Model
One of the most significant changes has been the widespread adoption of SaaS platforms. Business-critical operations increasingly rely on SaaS platforms (Software as a Service), such as Microsoft 365, CRM systems and collaboration tools.
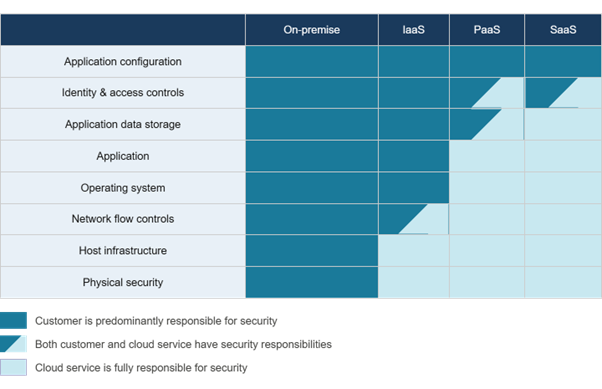
This shift has introduced a new layer of complexity to disaster recovery - particularly around ownership and accountability. Many organisations assume that SaaS platforms include disaster recovery. While SaaS providers typically ensure platform availability and some basic data retention, granular recovery, long-term retention, and point-in-time restoration often remain the customer's responsibility.
Responsibility for data resilience, recovery, and business continuity often remains with the customer as part of the shared responsibility model. This creates a critical gap: systems may be available, but the organisation may still be unable to recover its data or restore services in line with business requirements.
The table below breaks down how responsibilities are often allocated across the four main cloud deployment strategies, highlighting who is responsible for each element.
Operational Resilience and Regulatory Pressure
Regulatory expectations have also reshaped disaster recovery requirements. Organisations are increasingly required to demonstrate not only that recovery plans exist, but that they have been validated and can meet defined impact tolerances. This has elevated disaster recovery from a technical function to a core component of operational resilience and risk management.
Automation and Orchestrated Recovery
Modern disaster recovery increasingly relies on automation and orchestration to reduce recovery time and human error. Failover processes that were once manual are now increasingly scripted and orchestrated, enabling faster and more consistent recovery outcomes. This is particularly important in complex environments, where multiple systems and dependencies must be restored in a precise sequence.
Remote and Distributed Workers
Recovery is no longer confined to restoring systems in a single physical location. As organisations adopt cloud services and support distributed workforces, recovery design must now account for how users actually access systems.
User access, endpoint management and authentication all need to be factored into recovery design. If identity systems fail during a disaster event, staff may be unable to access even fully restored environments.
This means recovery can appear successful from an infrastructure perspective, while the business remains unable to operate.
It’s not just how you recover – it’s also where
Taken together, these shifts have fundamentally changed how organisations need to think about their in-house business continuity strategy or any disaster recovery services they take.
It is no longer enough to utilise a recovery service or solution around a single environment or location. Instead, organisations must consider how recovery operates across a mix of infrastructure types, service models and access points - all with different recovery capabilities and responsibilities.
This introduces a new challenge: not just how to recover systems, but where that recovery should take place, and how those environments are managed, secured and tested.
In practice, this means organisations must make deliberate decisions about where their recovery capability sits - balancing speed, cost, resilience and operational complexity.
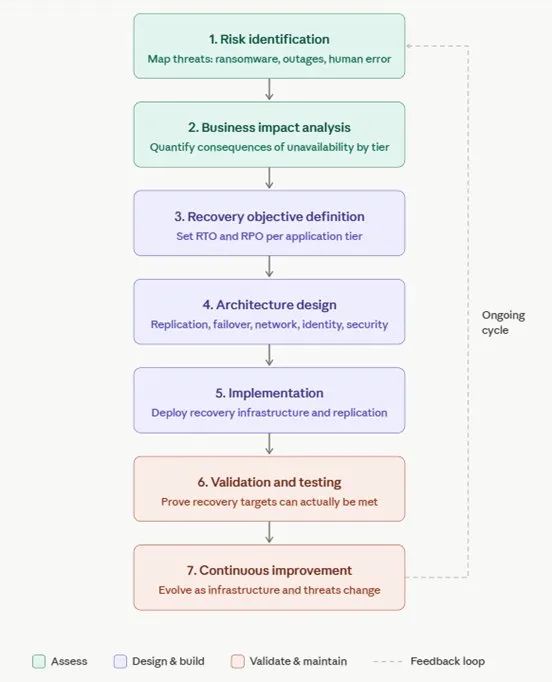
Exploring the disaster recovery lifecycle
Disaster recovery is often treated as a one-off project, but this approach often fails under real-world conditions, with many organisations only discovering gaps during their first incident.
DR is a capability that needs to be designed, implemented, validated and continually maintained. Organisations that treat disaster recovery planning as a tick-box exercise consistently find gaps when recovery is needed most.
A structured disaster recovery lifecycle provides a framework for building and maintaining this capability over time.
While approaches may vary, most effective strategies follow a series of core stages:
-
Risk identification: mapping the threat landscape relevant to your organisation, sector and infrastructure. This includes risks such as ransomware, infrastructure failure, cloud region outages, supply chain disruption and human error.
-
Business impact analysis (BIA): quantifying the operational, commercial and regulatory consequences of system unavailability across different timeframes. This forms the evidence base for setting your recovery priorities and investment decisions.
-
Recovery Objective definition: setting specific, measurable targets for data loss tolerance (RPO) and maximum acceptable downtime (RTO) for each application tier.
-
Architecture design: designing the technical recovery environment, including replication models, failover infrastructure, network configuration, identity recovery and security controls. This stage defines how recovery will actually be delivered in practice.
-
Implementation: deploying and configuring the recovery infrastructure, replication processes and monitoring capability. This is where strategy becomes operational.
-
Validation and testing: running structured DR tests to confirm that recovery targets can actually be met. Testing is the only way to move from a documented plan to a proven recovery capability
-
Continuous improvement: keeping DR current as infrastructure changes, applications evolve, cloud deployments expand, and threat models shift.